Introduction
Let’s assume you want a collection where you want to store key/value pairs. To store the key/value pair, pass both key and value and to get a value, provide the key and the collection will give you back the value associated with that key. This is what Map will help you with. Today we will learn HashMap that implements Map
HashMap
HashMap<K,V> is a class in Java Collection Framework that implements Map<K,V> interface. Here K indicates the type of key and V indicates the type of value. So, if you want to create a Map where key will be String and value will be Integer, you can write it like –
HashMap<String, Integer> map = new HashMap<String, Integer>(); |
To put a key/value pair, you have to use the put() method.
map.put("one", 1);map.put("two", 2); |
To access a value by key, you can use the get() method. The below statement will assign 2 to variable result.
int result = map.get("two"); |
To remove an item, you can use the remove() method.
map.remove("one"); |
To get the size (number of key/value pairs) of a Map, you can use the size() method.
map.size() |
Can we use only String as key?
No. You can use any java object as a key, but that object must override equals() and hashCode() methods. Value can be any object and it’s not mandatory for value objects to override equals() and hashCode() methods.
Also, HashMap doesn’t maintain the order in which key/value pairs are added. So if you iterate over a HashMap, it is not guaranteed that you will get the items in that same order in which they are added.
As Map contains key/value pairs, if we add multiple values with the same key and try to access the value by that key, will it return multiple values?
The answer is No. Let’s try this.
HashMap<String, Integer> map = new HashMap<String, Integer>();map.put("one", 1);map.put("two", 2);map.put("one", -1);System.out.println(map.get("one"));Output: -1 |
I hope you have guessed the behavior from the output. When you try to put multiple values against the same key, the latest value will replace previous values.
In other words, a Map cannot contain duplicate keys. If you try to add the same key multiple times, the Map will not add the key if it already exists, Map will just update the value against that key.
You can also have null as a key.
HashMap<String, Integer> map = new HashMap<String, Integer>();map.put(null, 100);map.put("one", 1);map.put(null, 200);map.put("two", 2);System.out.println(map);Output: {null=200, one=1, two=2} |
But there can be duplicate values. Map doesn’t care about the values as long as that is of expected type.
HashMap<String, Integer> map = new HashMap<String, Integer>();map.put("one", 1);map.put("value1", 200);map.put("value2", 200);System.out.println(map);Output: {value2=200, value1=200, one=1} |
How does HashMap work internally?
First of all, let’s look at the nested Node class within HashMap class. This is not the exact code. For simplicity, we will change the code a little bit. The source code may change a bit in different Java versions, but most parts are almost the same.
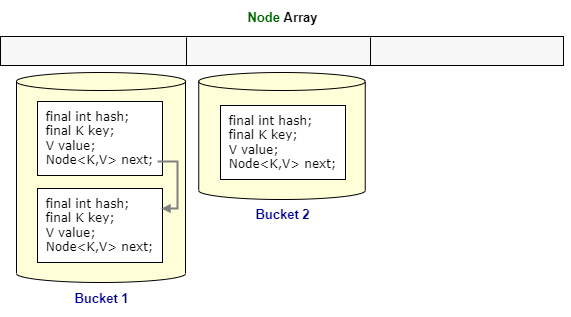
public class HashMap<K,V> implements Map<K,V> { Node<K,V>[] table; public HashMap() { table = new Node[16]; } static class Node<K,V> { final int hash; final K key; V value; Node<K,V> next; }} |
We can see, the Node class has four fields. We’ll understand the purpose of each field during discussing the methods of HashMap class.
When we create a HashMap using the default constructor, the HashMap creates an array of Node class with size 16.
Each index of this array is called a bucket.
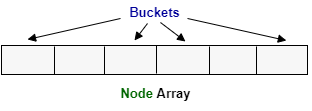
Each bucket can contain multiple Node objects. When there are multiple nodes in a single bucket, they are stored as LinkedList.
The put() method
When you put a value, you call the put(K key, V value) method. HashMap internally perform following steps –
- First the hashCode of the key object is calculated. Then this hashCode is converted into an integer
hashvalue using some formula (we can ignore this formula). - Then the bucket (index in Node array) is identified using a formula:
hash value & (table.length - 1). - Then a new Node object is created where: hash = hash value calculated at step 1, key = provided key, value = provided value, next = Node object if already present in the same bucket, otherwise it will be null.
- If the number of elements in the HashMap exceeds a
threshold(will discuss in a while), double the size of the Node array. - Add the newly created Node object to the identified bucket.
We should discuss the formula used to identify the bucket and the concept of threshold.
We said, to identify the bucket HashMap used the formula: hash value & (table.length - 1). The Bitwise AND (&) operator returns bit by bit AND of input values. If both bits are 1, it gives 1, else it shows 0.
For example, if the length of the Node array is 16 and the hash value is 35 then the bucket at index 3 will be selected.

Load factor and threshold
Now, let’s understand the threshold. The HashMap class contains instance variables called loadFactor. Default value of this field is .75. The load factor represents at what point the HashMap capacity should be increased to double. So the value .75 indicates, after storing the 12 (initial size 16 * .75) key/value pair into the HashMap, its capacity becomes 32.
Now the question is, why do we use the load factor and why do we increase the size of HashMap? The get operation of HashMap will slow down if there are too many items in the same bucket. Of course there can be multiple items in the same bucket, but it should not be too many. When there are multiple values in the same bucket, we consider that as a collision.
If we do not increase the bucket size (size of HashMap), as you put more items, multiple items will be landed in each bucket and eventually decrease the performance of get() operation. So, we must increase the size of the Map once a threshold is reached.
The load factor indicates that threshold. In other words, the load factor helps to decide when to increase the number of buckets. If the load factor is low, chances of collision will be reduced, but that might increase free buckets. So, this might increase space overhead. If the load factor is high, chances of free buckets will be reduced, but there will be more collisions. This will increase the lookup cost. The default load factor (.75) offers a good tradeoff between lookup time and space costs.
The get() method
When we call the get(Object key) method, we pass a key and get the corresponding value. HashMap internally follow below steps –
- First the hashCode of the key object is calculated. Then this hashCode is converted into an integer
hashvalue using some formula. - Then the bucket (index in Node array) is identified using a formula:
hash value & (table.length - 1). - Then all the Node objects are fetched from that bucked and the key field of those objects are matched with the input key using
equals()method. - Once the match is found, the value of the field value of the matched Node object is returned.
As you can see, if there are too many Node objects in the same bucket, more time will be required to match the Node with the input key which will eventually decrease the get() performance.
Other commonly used methods of HashMap
| Method | Description |
|---|---|
| void clear() | This method removes all of the elements from the Map. |
| boolean isEmpty() | This method returns true if the Map contains no elements. |
| int size() | This method returns the number of items in the Map. |
| containsKey(Object key) | Return true if the Map contains the key. |
| V remove(Object key) | Remove the key/value pair if present. |
| Set<K> keySet() | Returns a Set of keys contained in this map. |
| Collection<V> values() | Returns a Collection of values contained in this map. |
Example:
public class HashMapDemo { public static void main(String[] args) { HashMap<String, String> map = new HashMap<String, String>(); map.put("Key1", "Value1"); map.put("Key2", "Value2"); map.put("Key3", "Value3"); map.put("Key4", "Value4"); map.remove("Key2"); System.out.println(map.containsKey("Key4")); System.out.println(map.size()); System.out.println(map.isEmpty()); System.out.println(map.keySet()); System.out.println(map.values()); }}Output:true3false[Key1, Key4, Key3][Value1, Value4, Value3] |
How to iterate over HashMap
There are multiple ways, but below is one of the most commonly used techniques.
public class HashMapDemo { public static void main(String[] args) { HashMap<String, String> map = new HashMap<String, String>(); map.put("Key1", "Value1"); map.put("Key2", "Value2"); map.put("Key3", "Value3"); map.put("Key4", "Value4"); for (Entry<String, String> entrySet : map.entrySet()) { System.out.println("Key : " + entrySet.getKey() + ", Value : " + entrySet.getValue()); } }}Output:Key : Key2, Value : Value2Key : Key1, Value : Value1Key : Key4, Value : Value4Key : Key3, Value : Value3 |
As you said, HashMap doesn’t maintain the order in which key/value pairs are added. Is there any way to preserve that order?
Yes. Instead of HashMap, you have to use LinkedHashMap.
public class HashMapDemo { public static void main(String[] args) { LinkedHashMap<String, String> map = new LinkedHashMap<String, String>(); map.put("Key1", "Value1"); map.put("Key2", "Value2"); map.put("Key3", "Value3"); map.put("Key4", "Value4"); for (Entry<String, String> entrySet : map.entrySet()) { System.out.println("Key : " + entrySet.getKey() + ", Value : " + entrySet.getValue()); } }}Output:Key : Key1, Value : Value1Key : Key2, Value : Value2Key : Key3, Value : Value3Key : Key4, Value : Value4 |
That’s it for now. Hope you have enjoyed this tutorial. If you have any doubt, please ask in the comment section. I will try to answer that as soon as possible. Till then, bye bye.
One thought on “HashMap”
Comments are closed.